
Blog
Januar 10, 2018
Produktdaten enthalten oft eine große Anzahl von Attributen, die in der Regel getrennt werden müssen, um aussagekräftige Erkenntnisse über sie zu erhalten. Da die Unternehmen heute weltweit präsent sind, gibt es auch Anforderungen für die Lokalisierung: Unterstützung für mehrere Sprachen, Währungen, Maßeinheiten usw.
Um konsistente Produktinformationen über das gesamte Unternehmen und die Vertriebskanäle hinweg zu veröffentlichen, müssen die Informationen zunächst erfasst und aufbereitet werden, damit sie korrekt und aktuell sind.
Das Ziel der Aufbereitung von Produktstammdaten ist es, sicherzustellen, dass die Daten konsistent und von hoher Qualität sind. Inkonsistente, minderwertige Daten können zu Fehlern führen, die Markteinführung verlangsamen und die Kundenzufriedenheit beeinträchtigen.
Wir bei Onedot glauben, dass die Vorbereitung von Produktstammdaten idealerweise in diesen 8 Schritten durchgeführt wird
- Dateneingabe
- Extraktion von Attributen
- Produkt-Kategorisierung
- Schema-Mapping
- Integration von Daten
- Normalisierung der Attribute
- Goldene Schallplatte Generation
- Identifizierung der Produktvariante

Wandeln Sie zunächst alle Ihre Eingabedateien in eine flache Tabelle mit einem einheitlichen Schema um, die als Grundlage für alle weiteren Datenaufbereitungen dient.
Zweitens: Extrahieren Sie zusätzliche Attribute aus halbstrukturierten Informationen wie Produkttiteln und Produktbeschreibungen, um mehr strukturierte Informationen aus Ihren verfügbaren Daten zu gewinnen und Ihre Fähigkeit zu verbessern, Suchfilter zu füttern, Produkte korrekt zu kategorisieren und Produktvarianten zu identifizieren.
Bevor Sie mit der Datenintegration fortfahren, empfehlen wir Ihnen, Ihre Produkte zu kategorisieren, da das Schema-Mapping, die Attributnormalisierung und die Erstellung von Produktvarianten oft kategoriespezifisch sind. Im Idealfall sind Sie in der Lage, alle Ihre Produkte automatisch der wahrscheinlichsten Zielkategorie zuzuordnen, wobei jede Zuordnung ein Konfidenzniveau als Grundlage für die manuelle Validierung enthält.
Als Nächstes bilden Sie alle Eingabeattribute auf Ihre Zielattribute ab. Für Attribute, die nicht von der Zielstruktur abgedeckt werden, empfiehlt sich eine separate Auflistung als Grundlage für eine mögliche Anpassung des Zielschemas und zur Vermeidung von Informationsverlusten.
Sobald Sie mit Ihrer Schemaabbildung zufrieden sind, integrieren Sie die einzelnen Produkte aus Ihren Eingabedaten, indem Sie Ihre Attributwerte entweder unverändert oder gegebenenfalls auf vordefinierte Werte abbilden. Das Ergebnis ist ein einheitlicher Datensatz, den Sie bereits zur Befüllung Ihres PIM verwenden können.
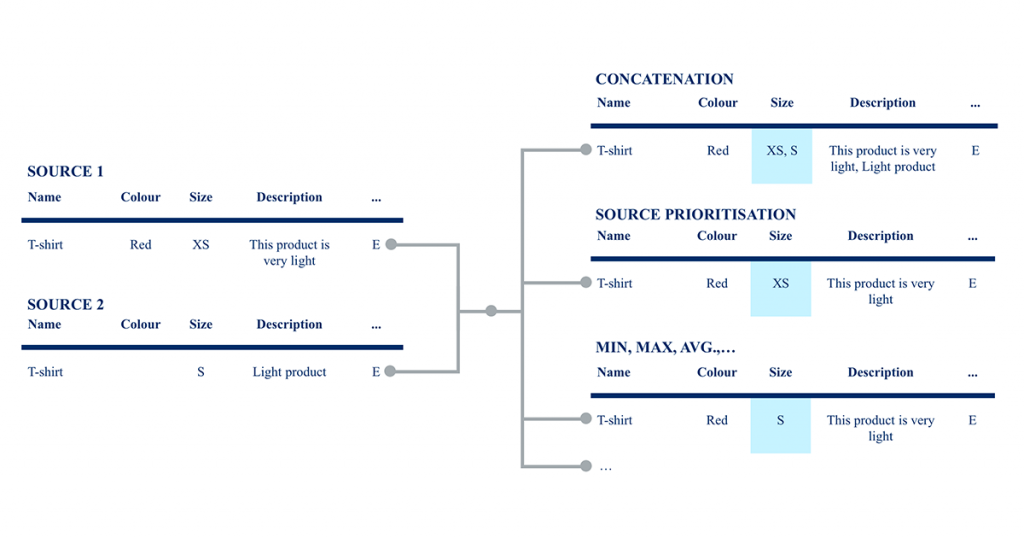
Es gibt jedoch noch 3 weitere Schritte, die wir Ihnen empfehlen, zu beachten:
- In der Regel möchten Sie Ihre Attributwerte normalisieren und umwandeln, um für Ihren Webshop großartige Suchfilter zu ermöglichen, die die Konversionsrate steigern und die Suchmaschinenoptimierung und das Marketing verbessern.
- Möglicherweise haben Sie Daten aus mehreren Eingabequellen für identische Produkte. In diesem Fall sollten Sie die verfügbaren Daten zu einem einheitlichen ("goldenen") Datensatz aggregieren, indem Sie eine bestimmte Strategie anwenden, z. B. indem Sie einer Quelle den Vorrang vor anderen geben, so dass ein einheitlicher, entduplizierter Satz Ihrer Produktstammdaten entsteht.
- Vielleicht möchten Sie Produktvarianten auf der Grundlage bestimmter Attribute wie Farbe, Größe usw. erstellen, um zu vermeiden, dass 95 % identische Produkte mehrfach auf Ihrer Website als einzelne Angebote angezeigt werden.
Schlussfolgerung
Die Aufbereitung von Produktstammdaten in großem Maßstab kann eine entmutigende Aufgabe sein, die viel manuelle Arbeit über lange Zeiträume mit unzähligen Iterationen und Feedbackschleifen erfordert. Die Wahl der richtigen Lösung, die einfach zu konfigurieren, in hohem Maße anpassbar und gleichzeitig skalierbar ist, kann jedoch enorme Auswirkungen auf den Umsatz und die Gewinnsteigerung haben. Sie wird dazu beitragen, den Datenverwaltungsprozess zu beschleunigen und die Kosten zu senken.
Seien Sie schneller und besser bei reduzierten Betriebskosten, indem Sie einen strukturierten Best-Practice-Prozess wie den oben genannten in Kombination mit einem hochmodernen KI-gestützten Datenaufbereitungsdienst anwenden.