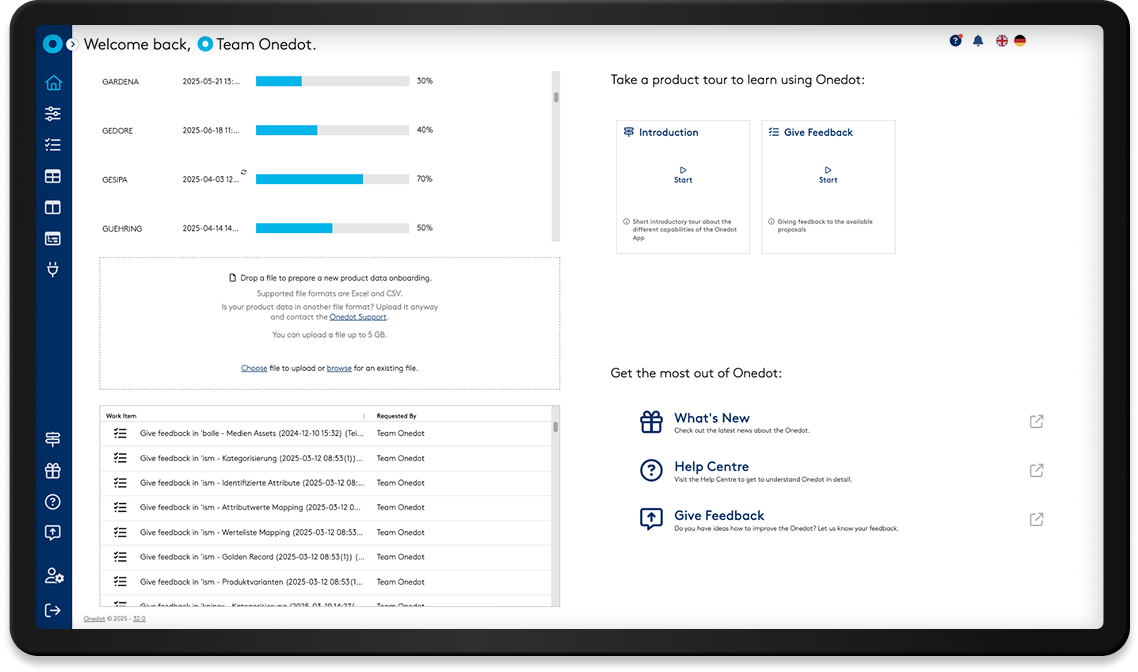
Make Product Data Work For You
Achieve more sales and a higher conversion rate at reduced costs with Onedot.
Reduce the duration of onboarding from months to days
Accelerate the market launch of products fivefold
Reduce manual effort by up to 70% with AI powered automation
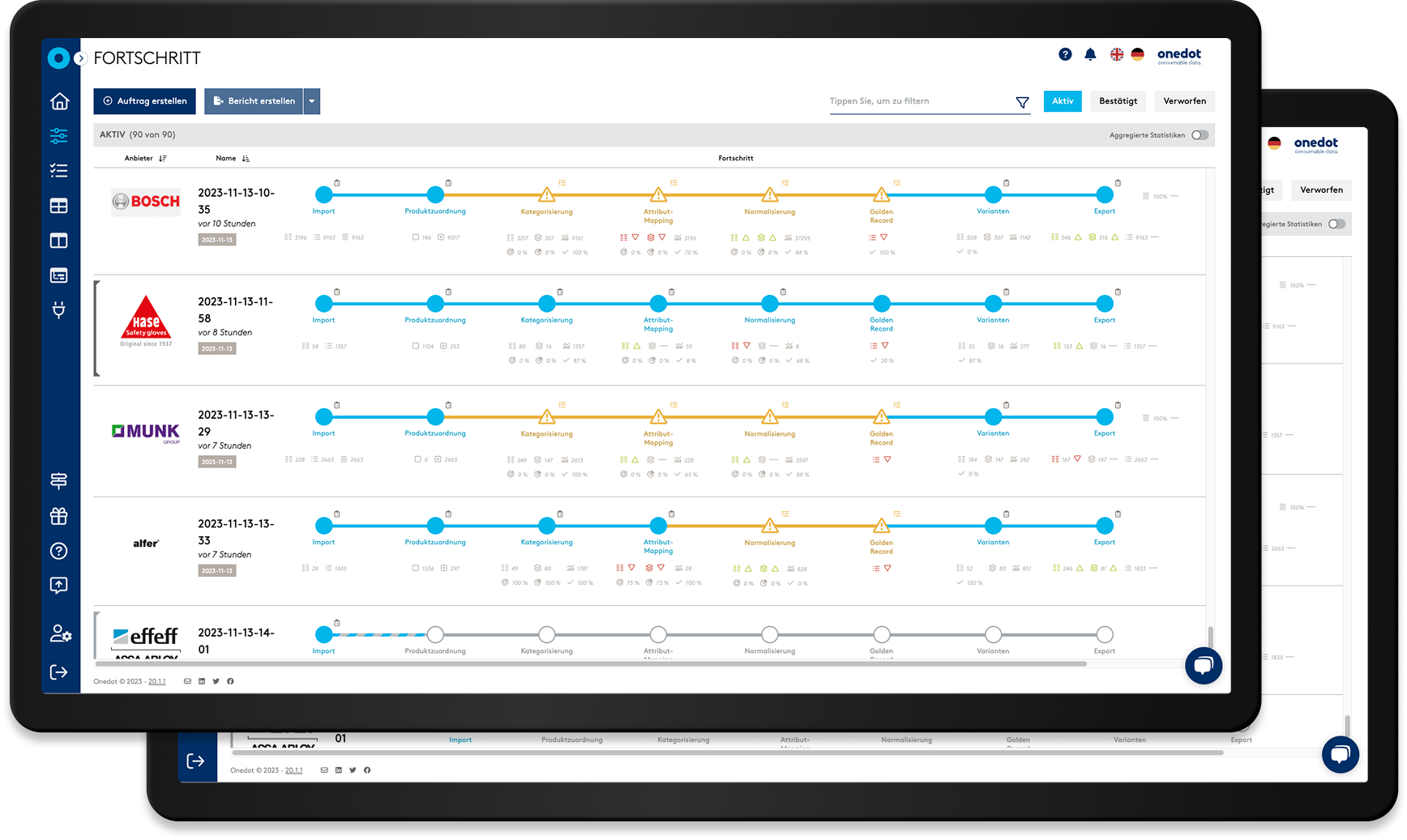
Simplify and Optimize With AI
Onedot puts powerful, custom-trained AI at the heart of product data transformation from mining and onboarding to classification and syndication. Built on over a decade of real-world learning and trained on 750M+ products from 1,000+ suppliers, our models deliver unparalleled automation, accuracy, and efficiency at scale.

Mine Hidden Product Data
Leverage Onedot’s advanced data mining to extract structured, high-quality content from fragmented sources like supplier websites, PDF catalogs, and data sheets. Even when suppliers fall short on information, Onedot fills the gaps.

Streamline Product Onboarding
Onedot streamlines onboarding to your ERP, PIM, or shop system. With the Supplier Portal, everyone collaborates in one platform. No emails, no chaos.
The result? Faster, cleaner imports and a smoother workflow from start to finish.
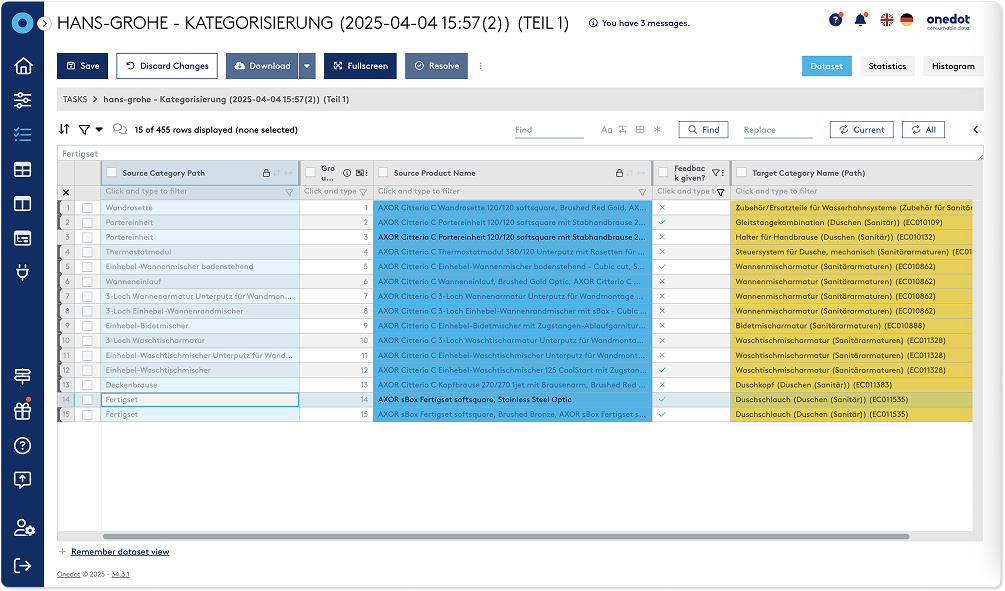
Automate Product Data Classification
Onedot automatically maps products to the right classification structure, aligning with standards like ETIM, ECLASS, or UNSPSC.
This ensures accurate, consistent listings across your sales channels, boosting visibility, searchability, and seamless integration with your digital ecosystem.
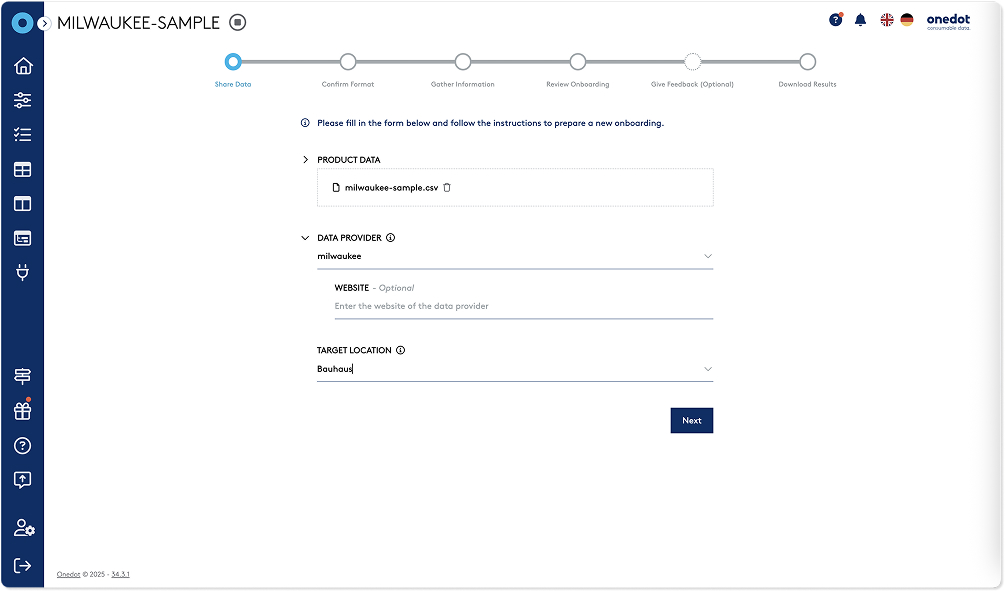
Syndicate With Precision At Scale
Syndicate product content to retailers, data platforms, and industry data pools seamlessly. With AI-powered mapping and customizable channel rules, it automates the delivery of high-quality data.
You stay in control of what’s published and where.

Easily Integrate With Your Existing Tech Stack
Onedot fits any existing tech stack by easily integrating with any PIM, DAM, ERP, eCommerce, and portal system. Designed to adapt to existing workflows, Onedot can source from and transform to any data model.
Feature Highlights
Onedot AI
Onedot delivers cutting-edge product data onboarding powered by AI, trained on over 750 million products and over 1000 suppliers.
Content Mining
Scrape data from supplier websites, PDF product catalogs, data sheets, and other fragmented sources and extract it into a rich and well-structured format.
Auto-Classification
Onedot automatically categorizes products and maps them to the correct sales channel and classification system. This ensures consistent, structured product data
Supplier Portal
Enhance your Supplier Experience by enabling direct, in-platform collaboration and onboarding with portals, templates, commenting, tasking, and streamlined data exchange.
Product Variants
Automatically generate product variants and group them so customers can find the right product variant faster by having them listed together.
Data Normalization
Automatically normalize text, numbers, convert units, or map a list of values. Need consistent sales text? Generate it over Onedot.
Golden Record
Support the creation of a complete product record by consolidating and enriching data from multiple sources. Compare existing information, merge relevant details, and fill gaps to generate the most accurate and comprehensive product dataset.
Text Extraction
The supplier doesn’t provide structured information? Onedot extracts product attributes from product descriptions and text, providing more information for filtering and searching.
Asset Management
Define which image to onboard, set the sequence of images, and apply transformations such as background removal, aspect ratio adjustments, format changes, and size optimization to meet your product data standards.